Detecting Googlebombs
I recently did a Googlebomb post over on the Google Public Policy Blog. I’ve talked about Googlebomb phenomenon before (also see more Googlebomb background here). Just as a reminder, a Googlebomb is a prank where a group of people on the web try to push someone else’s site to rank for a query that it didn’t intend to (and normally wouldn’t want to) rank for. Typically these queries tend to be unusual phrases such as “talentless hack” that don’t really have any existing strong results. Danny Sullivan asked a good question in this most recent round of coverage about Googlebombs:
I wanted to address that question. The short answer is that we do two different things — both of them algorithmic — to handle Googlebombs: detect Googlebombs and then mitigate their impact. The second algorithm (mitigating the impact of Googlebombs) is always running in our productionized systems. The first algorithm (detecting Googlebombs) has to process our entire web index, so in most typical cases we tend not to run that algorithm every single time we crawl new web data. I think that during 2008 we re-ran the Googlebomb detection algorithm 5-6 times, for example. You can think of it like this:
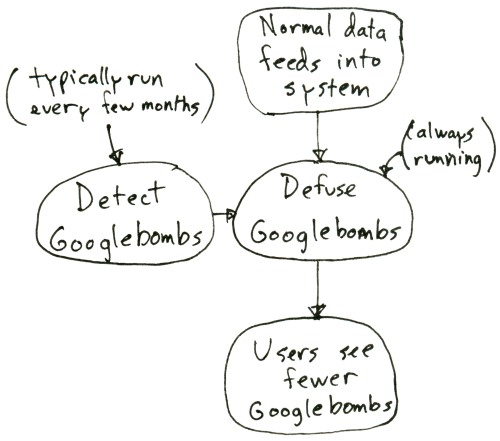
The defusing algorithm is running all the time, but the algorithm to detect Googlebombs is only run occasionally. We re-ran our algorithm last week and it detected both the [failure] and the [cheerful achievement] Googlebombs, so our system now minimizes the impact of those Googlebombs. Instead of a whitehouse.gov url, you now see discussion and commentary about those queries.
www.mattcutts.com
published @ January 29, 2009