Rewriting the Beginner’s Guide Part IX: Myths, Penalties and Spam
I'm currently working on re-authoring and re-building the Beginner's Guide to Search Engine Optimization, section by section. You can read more about this project here. Common Myths & Misconceptions About Search Engines Unfortunately, over the past 12 years, a great number of misconceptions have emerged about how the search engines operate and what's required to perform effectively. In this section, we'll cover the most common of these, and explain the "real story" behind the myth.
--------------------
In classical SEO times (the late 1990's), search engines had "submission" forms that were part of the optimization process. Webmasters & site owners would tag their sites & pages with information (this would sometimes even include the keywords they wanted to rank for), and "submit" them to the engines, after which a bot would crawl and include those resources in their index. For obvious reasons (manipulation, reliance on submitters, etc.), this practice was unscalable and eventually gave way to purely crawl-based engines. Since 2001-2, search engine submission has not only not been required, but is actually virtually useless. The engines have all publicly noted that they rarely use the "submission" URL lists, and that the best practice is to earn links from other sites, as this will expose the engines to your content naturally.
You can still see submission pages (for Yahoo!, Google,MSN/Live), but these are remnants of time long past, and are essentially useless to the practice of modern SEO. If you hear a pitch from an SEO offering "search engine submission" services, run, don't walk. Even if the engines did use the submission service to crawl your site, you'd be very unlikely to earn enough "link juice" to be included in their indices or rank competitively for search queries.
Meta Tags
Once upon a time, much like search engine submission, meta tags, in particular, the meta keywords tag, was an important part of the SEO process. You would include the keywords you wanted your site to rank for and when users typed in those terms, your page could come up in a query. This process was quickly spammed to death, and today, only Yahoo! among the major engines will even index content from the meta keywords tag, and even they claim not to use those terms for ranking, but merely content discovery. This subject has been covered in great detail by Danny Sullivan of Search Engine Land.
It is true that other meta tags, namely the title tag and meta description tag (which we've covered previously in this guide) are of critical importance to SEO best practices. And, certainly, the meta robots tag too, is an important tool for controlling spider access. However, SEO is not "all about meta tags;" at least, not anymore.
Keyword Stuffing & Keyword Density
Not surprisingly, a persistent myth in SEO revolves around the concept that keyword density - a mathematical formula that divides the number of words on a page by the number of instances of a given keyword - is used by the search engines for relevancy & ranking calculations and should therefore be a focus of SEO efforts. Despite being proven untruetime and again, this farce has legs, and indeed, many SEO tools feed on the concept that keyword density is an important metric. It's not. Ignore it and use keywords intelligently and with usability in mind. The value from an extra 10 instances of your keyword on the page is far less than earning one good editorial link from a source that doesn't think you're a search spammer.
Paid Search Helps Bolster Organic Results
Put on your tin foil hats; it's time for the most common SEO conspiracy theory - that upping your PPC spend will improve your organic SEO rankings (or, likewise, that lowering that spend can cause ranking drops). In all of the experiences I've ever witnessed or heard about, this has never been proven nor has it ever been a probable explanation for effects in the organic results. Google, Yahoo! & MSN/Live all have very effective Chinese Walls in their organizations to prevent precisely this type of crossover. At Google in particular, advertisers spending tens of millions of dollars each month have noted that even they cannot get special access of consideration from the search quality or web spam teams. So long as the existing barriers are in place, and the search engines cultures maintain their separation, I believe that this will remain a myth.
Search Engine Spam
--------------------
The practice of spamming the search engines - creating pages and schemes designed to artificially inflate rankings or abuse the ranking algorithms employed to sort content - has been rising since the mid-1990's. With payouts so high (at one point, a fellow SEO noted to me that a single day ranking atop Google's search results for the query "buy viagra" could bring upwards of $20,000 in affiliate revenue), it's little wonder that manipulating the engines is such a popular activity on the web. However, it's become increasingly difficult and, in my opinion, less and less worthwhile for two reasons.
First, search engines have learned that users hate spam. This may seem a trivial and obvious lesson, but in fact, many who study the field of search from a macro perspective believe that along with improved relevancy, Google's greatest product advantage over the last 10 years has been their ability to control and remove spam better than their competitors. While it's hard to say if this directly influenced their dramatic rise to lead in market share worldwide, it's undoubtedly something all the engines spend a great deal of time, effort and resources on - and with hundreds of the world's smartest engineers dedicated to fighting the practice, I'm loathe to ever recommend search spam as a winnable endeavor in the long term.
Second, search engines have done a remarkable job identifying scalable, intelligent methodologies for fighting manipulation and making it dramatically more difficult to adversely impact their intended algorithms. Concepts like TrustRank (which SEOmoz's Linkscape index leverages), HITS, statistical analysis, historical data and more, along with specific implementations like the Google Sandbox, penalties for directories, reduction of value for paid links, combatting footer links, etc. have all driven down the value of search spam and made so-called "white hat" tactics (those that don't violate the search engines' guidelines) far more attractive.
This guide is not intended to show off specific spam tactics (either those that no longer work or are still practiced), but, due to the large number of sites that get penalized, banned or flagged and seek help, we will cover the various factors the engines use to identify spam so as to assist SEO practitioners avoid problems. For additional details about spam from the engines, see Google's Webmaster Guidelines, Yahoo!'s Search Content Quality Guidelines & MSN/Live's Guidlines for Successful Indexing.
Page-Level Spam Analysis
--------------------
Search engines perform spam analysis across individual pages and entire websites (domains). We'll look first at how they evaluate manipulative practices on the URL level.
Keyword Usage
One of the most obvious and unfortunate spamming techniques, keyword stuffing, involves littering numerous repetitions of keyword terms or phrases into a page in order to make it appear more relevant to the search engines. The thought behind this - that increasing the number of times a term is mentioned can considerably boost a page's ranking is generally folly. Studies looking at thousands of the top search results across different queries have found that keyword repetitions (or keyword density) appear to play an extremely limited role in boosting rankings, and have a low overall correlation with top placement.
The engines have very obvious, and very effective ways of fighting this. Scanning a page for stuffed keywords is not a massively challenging task and the engines' algorithms are all up to the task. You can read more about this practice, and Google's views on the subject, in a blog post from the head of their web spam team - SEO Tip: Avoid Keyword Stuffing.
Manipulative Linking
One of the most popular forms of web spam, manipulative link acquisition relies on the search engines' use of link popularity in their ranking algorithms to attempt to artificially inflate these metrics and improve visibility. This is one of the most difficult forms of spamming for the search engines to overcome because it can come in so many forms. A few of the many ways manipulative links can appear include:
- Reciprocal link exchange programs, wherein sites create link pages that point back and forth to one another in an attempt to inflate link popularity. The engines are very good at spotting and devaluing these as they fit a very particular pattern. See this post for more about reciprocal links.
- Incestual or self-referential links, including "link farms" and "link networks" where fake or low value websites are built or maintained purely as link sources to artificially inflate popularity. The engines combat these through numerous methods of detecting connections between site registrations, link overlap or other common factors.
- Paid links, where those seeking to earn higher rankings buy links from sites and pages willing to place a link in exchange for funds. These sometimes evolve into larger networks of link buyers and sellers, and although the engines work hard to stop them (and Google in particular has taken dramatic actions), they persist in providing value to many buyers & sellers (see this post on paid links for more on that perspective and this post from Search Engine Land on the official word from Google & other engines).
- Low quality directory links are a frequent source of manipulation for many in the SEO field. A large number of pay-for-placement web directories exist to serve this market and pass themselves off as legitimate with varying degrees of success. Google often takes action against these sites by removing the PageRank score from the toolbar (or reducing it dramatically), but won't do this in all cases.
There are many more manipulative link building tactics that the search engines have identified and, in most cases, found algorithmic methods of reducing their impact. As new spam systems (like this new reciprocal link cloaking scheme uncovered by Avvo Marketing Manager Conrad Saam) emerge, engineers will continue to fight them with targeted algorithms, human reviews and the collection of spam reports from webmasters & SEOs.
Cloaking
A basic tenant of all the search engine guidelines is to show the same content to the engine's crawlers that you'd show to an ordinary visitor. When this guideline is broken, the engines call it "cloaking" and take action to prevent these pages from ranking in their results. Cloaking can be accomplished in any number of ways and for a variety of reasons, both positive and negative. In some cases, the engines may let practices that are technically "cloaking" pass, as they're done for positive user experience reasons. For more on the subject of cloaking and the levels of risks associated with various tactics and intents, see this post - White Hat Cloaking - from SEOmoz.
"Low Value" Pages
Although it may not technically be considered "web spam," the engines all have guidlines and methodologies to determine if a page provides unique content and "value" to its searchers before including it in their web indices and search results. The most commonly filtered types of pages are affiliate content (pages whose material is used on dozens or hundreds of other sites promoting the same product/service), duplicate content (pages whose content is a copy of or extremely similar to other pages already in the index) and dynamically generated content pages that provide very little unique text or value (this frequently occurs on pages where the same products/services are described for many different geographies with little content segementation). The engines are generally against including these pages and use a variety of content and link analysis algorithms to filter out "low value" pages from appearing in the results.
Domain Level Spam Analysis
--------------------
In addition to watching individual pages for spam, engines can also identify traits and properties across entire root domains or subdomains that could flag them as spam signals. Obviously, excluding entire domains is tricky business, but it's also much more practical in cases where greater scalability is required.
Linking Practices
Just as with individual pages, the engines can monitor the kinds of links and quality of referrals sent to a website. Sites that are clearly engaging in the manipulative activities described above on a consistent or seriously impactful way may see their search traffic suffer, or even have their sites banned from the index. You can read about some examples of this from past posts - Widgetbait Gone Wild, What Makes a Good Directory and Why Google Penalized Dozens of Bad Ones, Google's Sandbox Still Exists: Exemplified by Grader.com and How to Handle a Google Penalty - And, an Example from the Field of Real Estate.
Trustworthiness
Websites that earn trusted status are often treated differently from those who have not. In fact, many SEOs have commented on the "double standards" that exist for judging "big brand" and high importance sites vs. newer, independent sites. For the search engines, trust most likely has a lot to do with the links your domain has earned (see these videos on Using Trust Rank to Guide Your Link Building and How the Link Graph Works for more). Thus, if you publish low quality, duplicate content on your personal blog, then buy several links from spammy directories, you're likely to encounter considerable ranking problems. However, if you were to post that same content to a page on Wikipedia and get those same spammy links to point to that URL, it would likely still rank tremendously well - such is the power of domain trust & authority.
Trust built through links is also a great methodology for the engines to employ in considering new domains and analyzing the activities of a site. A little duplicate content and a few suspicious links are far more likely to be overlooked if your site has earned hundreds of links from high quality, editorial sources like CNN.com, LII.org, Cornell.edu and similarly reputable players. On the flipside, if you have yet to earn high quality links, judgments may be far stricter from an algorithmic view.
Content Value
Similar to how a page's value is judged against criteria such as uniqueness and the experience it provides to search visitors, so too does this principle apply to entire domains. Sites that primarily serve non-unique, non-valuable content may find themselves unable to rank, even if classic on and off page factors are performed acceptably. The engines simply don't want thousands of copies of Wikipedia or Amazon affiliate websites clouding up their index, and thus take algorithmic and manual review methods to prevent this.
Penalty Signs & Re-Inclusion Procedures
--------------------
How to Know If Your Site's Been Penalized
It can be tough to know if your site/page actually has a penalty or if things have changed, either in the search engines' algorithms or on your site that negatively impacted rankings or inclusion. Before you assume a penalty, check for:
- Errors on your site that may have inhibited or prevented crawling
- Changes to your site or pages that may have changed the way search engines view your content (on-page changes, internal link structure changes, content moves, etc.)
- Sites that share similar backlink profiles, and whether they've also lost rankings - when the engines update ranking algorithms, link valuation and importance can shift, causing ranking movements.
Once you've ruled these out, follow this flowchart for more specific advice:
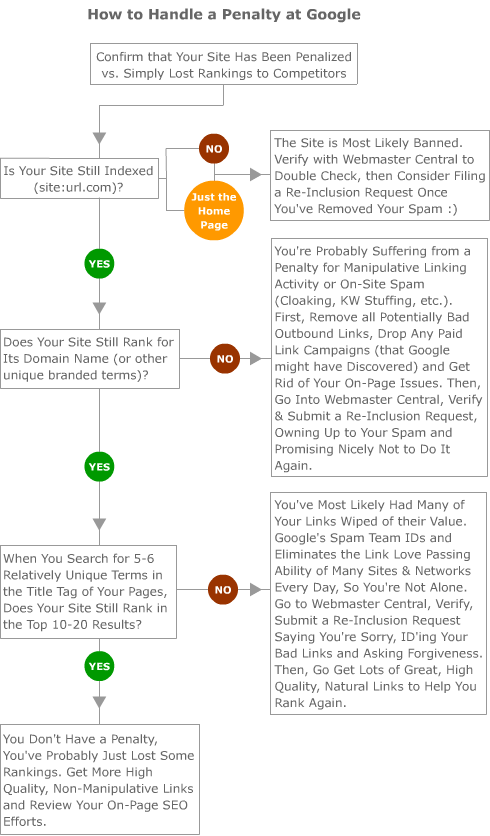
While this chart's process won't work for every situation, the logic has been uncanny in helping us identify spam penalties or mistaken flagging for spam by the engines and separating those from basic ranking drops. This page from Google (and the embedded YouTube video) may also provide value on this topic.
Getting Penalties Lifted
The task of requesting re-consideration or re-inclusion in the engines is painful and often unsuccessful. It's also, sadly, rarely accompanied by any feedback to let you know what happened or why. However, it is important to know what to do in the event of a penalty or banning - hence, the following recommendations:
- If you haven't already, register your site with the engine's Webmaster Tools service (Google's, Yahoo!'s, Live's). This registration creates an additional layer of trust and connection between your site and the webmaster teams.
- Make sure to thorougly review the data in your Webmaster Tools accounts, from broken pages to server or crawl errors to warnings or spam alert messages. Very often, what's initially perceived as a mistaken spam penalty is, in fact, related to accessibility issues.
- Send your re-consideration/re-inclusion request through the engine's Webmaster Tools service, rather than the public form - again, creating a greater trust layer and a better chance of hearing back.
- Full disclosure is critical to getting consideration. If you've been spamming, own up to everything you've done - links you've acquired, how you got them, who sold them to you, etc. The engines, particularly Google, want the details, as they'll apply this information to their algorithms for the future. Hold back, and they're likely to view you as dishonest, corrupt or simply incorrigable (and fail to ever respond).
- Remove/fix everything you can. If you've acquired bad links, try to get them taken down. If you've done any manipulation on your own site (over-optimized internal linking, keyword stuffing, etc.), get it off before you submit your request.
- Get ready to wait - responses can take weeks, even months, and re-inclusion itself, if it happens, is a lengthy process. Hundreds (maybe thousands) of sites are penalized every week, so you can imagine the backlog the webmaster teams encounter.
- If you run a large, powerful brand on the web, re-inclusion can be faster by going directly to an individual source at a conference or event. Engineers from all of the engines regularly participate in search industry conferences (SMX, SES, Pubcon, etc.) and the cost of a ticket can easily outweight the value of being re-included more quickly than a standard request might take.
Be aware that with the search engines, lifting a penalty is not their obligation or responsibility. Legally (at least, so far), they have the right to include or reject any site/page for any reason (or no reason at all). Inclusion is a privilege, not a right, so be cautious and don't apply techniques you're unsure or skeptical of - or you could find yourself in a very rough spot.
I'm getting pretty excited here. Just one more section to go before the appendices, and then it's home free!
As always, feedback, corrections, suggestions and edits are greatly appreciated.
www.seomoz.org
published @ March 17, 2009